March 09, 2020: FLOE infrastructure Continuation
- Justin Obara
- Cindy Li
Owned by Justin Obara
Present: Cindy, Justin, Jutta, Michelle, Ned, Philip, Ted,
Agenda
- Jutta continues the talk she didn’t finish in the last meeting
- Discussion of a draft diagram of the high level implementation structure
Notes:
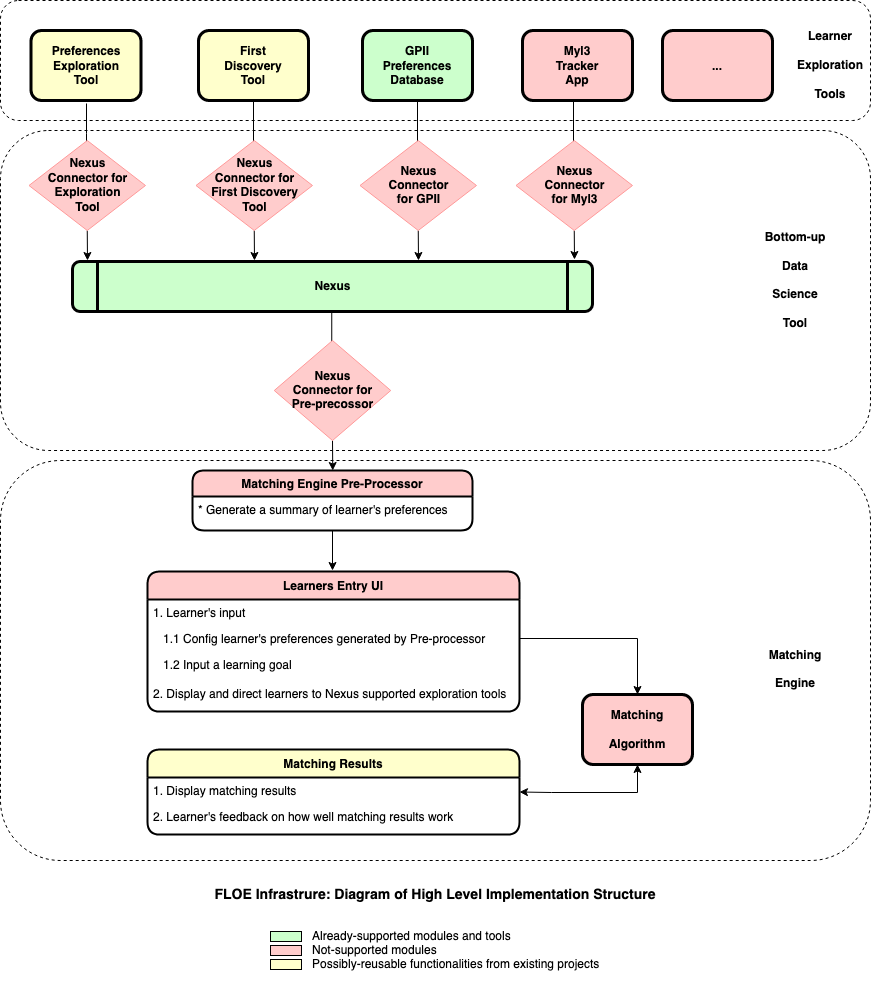
Requirement challenges:
- Learners can control 3 parts to influence the matching:
- Learning goals
- Configure the preprocessor generated summary of learning needs/preferences
- Feedback on matching results
Are these enough for the matching engine to be non-black box?
- Large data sets to train algorithms
- What other exploration tools can learners use to discover their learning needs?
- Where to search OER material? Wild web?
Technical Challenges:
- Preprocessor algorithm
- Matching algorithm
- How to identify each learner across all exploration tools and platforms
3 main direction of WeCount:
- Address data gaps through co-design, challenge workshops that data related problems are not addressed
- Identify accessibility issues of existing data science tools. Address these through co-design.
- Explore the possibilities of moving against the bias, especially deep learning / big data based systems.
Floe infrastructure is the Floe match within WeCount
Issues with the diagram:
- Instead of letting learners config a set of preferences, machine learning should be applied to understand how learners learn better
- Instead of watching learners to discover their preferences, learners should be given a tool to track and record their preferences
The actual understanding of how learners learn better, such as kids learning math thru dinosaurs
Next meeting: Tomorrow 1-2PM