From a 'concept' to a 'term'
We are building a registry of common terms to be used by those wanting to describe access needs and then resources or parts of resources to match those needs. Some needs will of interest to many people and some to just a few people but very important.
In all cases. we are developing a vocabulary for describing something - this is metadata. Data is what is described and metadata is description of it. As metadata has been used for 15 years in the digital world, there are lots of practices that have been shown to work, and lots that have failed, and there is a huge amount of metadata out there. I, therefore, cannot accept that this group is doing something completely original and that ways of working need to be invented.
Because most resources are already described in a number of ways by a number of different people/entities for a number of different purposes, it makes good sense to me to make our metadata/vocabulary available for combination with others' metadata as well as useful to us. interoperability seems to be a major factor in the utility of metadata - so I have it high on my agenda always.
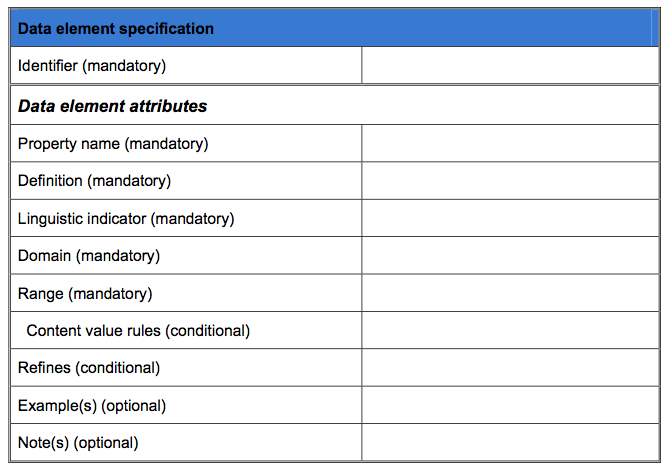
To have machines working with semantics, it has become necessary to provide for the requirements of the computer languages and systems people use. A simple table of characteristics for the creation of 'semantic strings' follows. I believe that each characteristic is very important and useful. Hence, this is the table I will be arguing should be in the standard 24751 Part 2 for the registry. If, for no other reason, unless that info is provided for each concept that becomes a term, the terms will not be usable in the MLR and that is something everyone agreed it would be. I also think it'd be good if we did not invent a whole lot of words that cannot be used by the search engines because they are not compatible/interchangeable with, for example, the schema.org terms, or the terms used by libraries, museums, galleries, government etc for their resources in countries like the UK, the USA, Canada, Australia, most European countries, etc.....
The other point that I think bodes well for using this table is that immediately all the definitions, and the table, can be adopted from an ISO standard that has been adopted as a European standard, an Australian standard, etc.
Finally, there may be some confusion about the 'refines' attribute of a term. There seems to be strong resistance for using ontologies etc which is odd given that most people would love them but just don't know how to build them, but apparently they are not relevant here???? I think they are used so that those with other vocabularies have some way of relating theirs and this one - but perhaps some don't think this is of interest? Anyway, by having the 'refines' info, it is really helpful to people who have a system developed when a new term comes along. If they already have the term that it refines, they can immediately use it. In the DC world we call this the 'dumb-down' rule - not politically correct - but it is a very useful strategy. I highly recommend it.
So here is the table from 19788-1 6.3.
(It should be noted that it describes 'data elements'. These are the things that have values - what we call the vocab, so the 'data elememts' are the 'terms' in our language. Metadata is odd - it is data about data so it, itself, as well as the descriptions of it, are data - hence the 'data elements'.)